|
shortname
|
Name in Tables
|
Description of variable:
|
| picnum |
Picture ID Number |
An individual picture ID with the word type abbreviation and a unique number is given to each item. Please note that the items ARE NOT in alphabetical order (due to differences in the predetermined and the dominant names, like "baby carriage" and "stroller"). |
| ename |
Dominant Response |
Only the valid responses (see below) were used for determining the target name, and for further analyses. Once the set of valid responses had been determined, the target name was defined as the "dominant response", i.e., the name that was used by the largest number of subjects. In the case of ties (two responses uttered by exactly the same number of subjects) three criteria were used to choose one of the two or more tied responses as the target. (1) the response closest to the intended target (i.e., the hypothesized target name used to select stimuli prior to the experiment), (2) the singular form if singular and plural forms were tied, and (3) the form that had the largest number of phonological variants in common. |
| Error coding - only valid responses were used for for further analyses. |
| egoodrt |
% Valid response |
Valid response refers to all the responses with a valid (codable) name and usable, interpretable response times (no coughs, hesitations, false starts, or prenominal verbalization like "that's a ball"). Any word articulated completely and correctly is kept for the evaluation, except for expressions that are not intended namings of the presented object, like "I don't know". 100% is the total number of subjects. |
| enoname |
% No response |
Invalid response refers to all the responses with an invalid RT (i.e., coughs, hesitations, false starts, prenominal verbalizations) or a missing RT (the participant did produce a name, but it failed to register with the voice key). 100% is the total number of subjects. |
| ebadrt |
% Invalid response |
No response refers to any trial in which the participant made no verbal response of any kind. 100% is the total number of subjects. |
| Name agreement: |
| etype |
Number of Types |
The number of alternative names for each picture was determined by "Number of types" (i.e., number of different names provided on valid trials, including the target name). |
| estatu |
H statistics |
The "H statistic" or H Stat (also called U statistic), a measure of response agreement that takes into consideration the proportion of subjects producing each alternative. 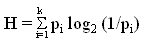 where where
pi = proportion of subjects producing the i-th name.
An increasing H value indicates decreasing name agreement, 0 refers to perfect name agreement (following Snodgrass and Vanderwart, 1980).
When calculating the proportion of subs, 100% = subject number. |
| Lexical Coding - Percent Name Agreement: All valid responses were coded into different lexical categories in relation to the target name, using the same criteria. |
| elex1 |
% Lex 1dom |
Percent name agreement "Lex1dom" was defined as the proportion of all valid trials (a codeable response, with a usable RT) on which participants produced the target name. 100% is the total number of valid responses. |
| elex2 |
% Lex 2phon |
"Lex2phon" is the percent of all codable responses with a valid RT that were classified as a morphological variant of the dominant name. This includes any morphological or morphophonological alteration of the target name, defined as a variation that shares the word root or a key portion of the word without changing the word's core meaning. Examples would include diminutives (e.g., "bike" for "bicycle"; "doggie" for "dog"), plural/singular alternations (e.g., "cookies" when the target word was "cookie"), reductions (e.g., "thread" if the target word was "spool of thread") or expansions (e.g., "truck for firemen" if the target word was "fire truck"). 100% is the total number of valid responses. |
| elex3 |
% Lex 3syn |
"Lex3syn" refers to the ratio of codeable responses on which a synonym was produced. Synonyms for the target name differ from Code 2 because they do not share the word root or key portion of the target word). With this constraint, a synonym was defined as a word that shared the same truth value conditions as the target name (e.g., "couch" for "sofa" or "chicken" for "hen"). 100% is the total number of valid responses. |
| elex4 |
% Lex 4err |
"Lex4err" refers to the percent of all codable responses with a valid RT on which participants produced a response that failed to meet criteria for Lexical Codes 1–3. This "error/other" category included superordinate names like "animal" or "food", or hyponyms (e.g., "animal" for "dog"), semantic associates that share the same class but do not have the target word's core meaning (e.g., "cat" for "dog"), part-whole relations at the visual-semantic level (e.g., "finger" for "hand"), and all frank visual errors or completely unrelated responses. 100% is the total number of valid responses. |
| elex13 |
% Lex 1-3 Lenient Name Agreement |
A summary score that conflates Lexical Codes 1, 2, and 3 (targets + morphophonological variants + synonyms). elex13 = elex1+elex2+elex3. This "lenient" score for name agreement has been used in other picture-naming studies, and sometimes yields different results compared with the more conservative measure in which name agreement refers to production of the target name only. |
| Reaction time: |
| erttot |
RT total MEAN |
"RT total MEAN" refers to mean reaction times across all valid trials, regardless of the content of that response. |
| estdtot |
RT total STD |
"RT total STD" refers to the standard deviation of reaction times across all valid trials, regardless of the content of that response. |
| erttar |
RT target MEAN |
"RT target MEAN" refers to mean latency for dominant responses only. |
| estdtar |
RT target STD |
"RT target STD" refers the standard deviation of reaction times for dominant responses only. |
| ert2 |
RT Lex2phon MEAN |
"RT Lex2phon MEAN" refers to mean latency of responses categorized as morphological variant of the dominant name "Lex2phon" (see details above). For some items empty cells signal that there were not enough valid responses within this lexical category to calculate variable value (minimum 2). |
| ert3 |
RT Lex3syn MEAN |
"RT Lex3syn MEAN" refers to mean latency of responses categorized as synonyms of the dominant response (see details above). For some items empty cells signal that there were not enough valid responses within this lexical category to calculate variable value (minimum 2). |
| ert4 |
RT Lex4err MEAN |
"RT Lex4err MEAN" refers to mean latency of responses categorized as error or other as compared to the dominant response "Lex4err" (see details above). For some items empty cells signal that there were not enough valid responses within this lexical category to calculate variable value (minimum 2). |
| Features of the dominant response and picture charateristics: |
| esames |
Items with shared name |
The "shared name" variable reflects the fact that some dominant names were used for more than one picture. The most extreme example is the single word "cut," which was used as the dominant name for five different action pictures (originally selected to elicit "peel", "slice", "dissect", "clip", and "cutting a paper with scissors"). Items that share the same dominant name with at least one other picture were specified by a dichotomous variable (1 = shared name; 0 = no shared name). |
| ovcjpg |
Obj. Vis. Complexity (KB) |
Estimates of objective visual complexity were obtained for the picture itself, based on the size of the digitized stimuli picture files. The black-and-white simple line drawings were scanned and saved as (300 x 300 pixel) Macintosh PICT file format, each in a separate file. A demo version of the handmade software utility Image Alchemy 1.8 (Woehrmann et al., 1994) was used to convert the stimuli to various graphics file formats. Over 30 different file types and degrees of compression for the 520 object and 275 action pictures were computed, and JPEG (high quality - low compression) was selected according to it's close correlation with subjective visual complexity and other variables (for details see Szekely & Bates, 2000). In Image Alchemy 1.8 the file type description was: Joint Photographic Experts Group with default Huffman coding, high quality - low degree of compression: 98 (on a scale from 1-100) was used with the syntax: -j98. |
| esyll |
Length in syllables |
Length of the dominant response in phonological syllables. |
| echar |
Length in characters |
Length of the dominant response as measured by the number of characters in the dominant response (spaces between multiwords are not counted). |
| efric |
Initial frication |
Presence/absence of a fricative or affricate in the initial consonant is a variable that has been reported to influence the time required for a response to register on the voice key. Items that have a dominant name with a fricative as initial consonant were specified by a dichotomous variable (1 = dominant name starts with a fricative; 0 = does not). Examples of initial frication in a word: challenge, fountain, his, shower, skate, vowel, zebra, jargon, this). |
| lnefreq |
Ln Frequency (CELEX) |
Frequency counts were taken from the CELEX Lexical database (Baayen, Piepenbrock, & Gulikers, 1995). In accordance with Snodgrass and Yuditsky (1996), log natural transformation ln (1 + raw frequency count) was applied to normalize the frequency measure for use in correlational analyses. |
| ecdi |
Objective AOA (CDI) |
An objective measure of age of acquisition (AoA) from published norms for the American version of the MacArthur Communicative Development Inventories, or CDI (Fenson et al., 1994). The CDI is based (inter alia) on concurrent parent report of vocabulary development in very large samples of children, collected in a recognition-memory format with a large checklist of words that are likely to be acquired between 8 and 30 months. For our purposes here, the CDI yields a simple 3-point scale: 1 = words acquired (on average) between 8 and 16 months; 2 = words acquired (on average) between 17 and 30 months; 3 = words that are not acquired in infancy (> 30 months). |
| ovcjpg |
Obj. Vis. Complexity (KB) |
Estimates of objective visual complexity were obtained for the picture itself, based on the size of the digitized stimuli picture files. The black-and-white simple line drawings were scanned and saved as (300 x 300 pixel) Macintosh PICT file format, each in a separate file. A demo version of the handmade software utility Image Alchemy 1.8 (Woehrmann et al., 1994) was used to convert the stimuli to various graphics file formats. Over 30 different file types and degrees of compression for the 520 object and 275 action pictures were computed, and JPEG (high quality - low compression) was selected according to it's close correlation with subjective visual complexity and other variables (for details see Szekely & Bates, 2000). In Image Alchemy 1.8 the file type description was: Joint Photographic Experts Group with default Huffman coding, high quality - low degree of compression: 98 (on a scale from 1-100) was used with the syntax: -j98. |
| esames |
Items with shared name |
The "shared name" variable reflects the fact that some dominant names were used for more than one picture. The most extreme example is the single word "cut," which was used as the dominant name for five different action pictures (originally selected to elicit "peel", "slice", "dissect", "clip", and "cutting a paper with scissors"). Items that share the same dominant name with at least one other picture were specified by a dichotomous variable (1 = shared name; 0 = no shared name). |
| ecomplx |
Complex words |
Word complexity is another dichotomous variable, 1 was assigned to any item on which the dominant response was a plural, a compound word or a periphrastic (multiword) construction. (1 = complex word; 0 = not). |
| objnum |
Conceptual Complexity |
Most of our object stimuli depict a single object against a minimal background. In contrast, the action pictures all involve at least one person, animal or object, and many of them involve two or more protagonists. This is a necessary by-product of the relational meanings that underlie most action verbs. Conceptual Complexity refers to our own subjective rating of the number of objects, animals or persons depicted in each stimulus. These counts applied at the level of the whole object. For example, body parts were not counted separately in pictures of a whole person, nor were separate counts given to the multiple elements in a mass noun (e.g., individual grapes in a cluster of grapes). Surrounding props or substrates for an action were counted separately only if they were critical to the interpretation of the action (e.g., a schematic line indicating the floor or the base of a wall was not counted as a separate object, but the diving board beneath a diving man was counted). |
